
Lazily Accessing Remotely Stored Data#
In this tutorial, we will go through how to access an AnnData object from a remote store using new functionality, experimental anndata.experimental.read_lazy() + anndata.experimental.read_elem_lazy() functions. The same idea, loading data lazily with minimal overhead on request, also applies to on-disk data. Broadly then, this is a new way of accessing what was has been called “backed” data previously. Let’s get started.
You’ll need to install scanpy "anndata[lazy]" along with "zarr[remote]" for obstore + fsspec (you’ll need requests aiohttp as well for fsspec).
%load_ext autoreload
%autoreload 2
from anndata.experimental import read_lazy, read_elem_lazy
import anndata as ad
import zarr
import scanpy as sc
import os
from zarr.storage import ObjectStore
from obstore.store import GCSStore
First we set up a custom store for tracking how many requests we are making. This is just a light wrapper around zarr.storage.FsspecStore that prints when a key has been accessed. For more performant remote file access, users can try the experimental zarr.storage.ObjectStore. This wrapper will allow us to see exactly which chunks we access, helpful for debugging but also understanding.
class AccessTrackingStore(zarr.storage.FsspecStore):
_keys_hit = set()
async def get(self, key, *args, **kwargs):
res = await super().get(key, *args, **kwargs)
if key not in self._keys_hit and res is not None:
print(key, ' accessed!')
self._keys_hit.add(key)
return res
The dataset stored on Google Cloud and used in this notebook originally came from the COVID-19 Cell Atas (entry “Bronchoalveolar lavage fluid”) and can be visualized using Vitessce, thus demonstrating the power of truly accessible remote data. Thank you to the HIDIVE Lab for hosting this data.
store = AccessTrackingStore.from_url("https://vitessce-demo-data.storage.googleapis.com/anndata-demos/BALF_VIB-UGent_processed_cleaned.zarr/", read_only=True)
# See https://github.com/zarr-developers/zarr-python/issues/3954 for info on why we use the URL directly
# store = zarr.storage.ObjectStore(store=GCSStore("vitessce-demo-data.storage.googleapis.com/anndata-demos/BALF_VIB-UGent_processed_cleaned.zarr"), read_only=True)
Note
Use the load_annotation_index=True argument to prevent loading of the actual index. This should speed up the first-load time. This is very helpful for loading many datasets at once
load_annotation_index = True
adata = read_lazy(zarr.open_consolidated(store, mode="r"), load_annotation_index=load_annotation_index)
.zattrs accessed!
.zgroup accessed!
.zmetadata accessed!
obs/_index/1 accessed!
obs/_index/0 accessed!
obs/_index/5 accessed!
obs/_index/6 accessed!
obs/_index/7 accessed!
obs/_index/3 accessed!
obs/_index/4 accessed!
obs/_index/2 accessed!
raw/var/_index/0 accessed!
raw/var/_index/1 accessed!
var/_index/0 accessed!
adata
AnnData object with n_obs × n_vars = 275056 × 24740
obs: 'orig.ident', 'Age', 'Sex', 'Race', 'Ethnicity', 'BMI', 'Pre-existing heart disease', 'Pre-existing lung disease', 'Pre-existing kidney disease', 'Pre-existing diabetes', 'Pre-existing hypertension', 'Pre-existing immunocompromised condition', 'Smoking', 'SARS-CoV-2 PCR', 'SARS-CoV-2 Ab', 'Symptomatic', 'Admitted to hospital', 'Highest level of respiratory support', 'Vasoactive agents required during hospitalization', '28-day death', '28-day outcome', 'Disease classification', 'Organ System', 'Source', 'Days since hospital admission', 'SOFA', 'Technology', 'Method', 'CITE-Seq panel', 'Reference', 'Institute', 'Creation date', 'Annotation'
var: 'feature_type', 'gene_id'
obsm: 'X_umap'
layers: 'X_csc'
Great! We can see that with only a few requests, we can now view all the columns available in this new AnnData object. This is a great start towards understanding what our data is.
Immediately, we see that this is some sort of COVID-19 dataset (from https://www.covid19cellatlas.org/index.patient.html, “Bronchoalveolar lavage fluid”). Now, let’s try to do some science and see how this new object works.
Note the type of obs - a wrapper anndata.experimental.backed.Dataset2D around an xarray.Dataset. More info can be found at their homepage: https://docs.xarray.dev/, but xarray gives AnnData much of the functionality of Pandas while keeping things lazy-loaded. You will never have to instantiate a anndata.experimental.backed.Dataset2D on your own. You can always set obs or var with a Dataset and anndata will take care of validating it (much like a pandas.DataFrame).
adata.obs.ds
obs/orig.ident/categories/0 accessed!
obs/Age/categories/0 accessed!
obs/Sex/categories/0 accessed!
obs/Race/categories/0 accessed!
obs/Ethnicity/categories/0 accessed!
obs/BMI/categories/0 accessed!
obs/Smoking/categories/0 accessed!
obs/28-day outcome/categories/0 accessed!
obs/Organ System/categories/0 accessed!
obs/Source/categories/0 accessed!
obs/Technology/categories/0 accessed!
obs/Method/categories/0 accessed!
obs/CITE-Seq panel/categories/0 accessed!
obs/Reference/categories/0 accessed!
obs/Institute/categories/0 accessed!
obs/Annotation/categories/0 accessed!
<xarray.Dataset> Size: 75MB
Dimensions: (_index: 275056)
Coordinates:
* _index (_index) object 2MB 'C...
Data variables: (12/33)
orig.ident (_index) category 2MB ...
Age (_index) category 2MB ...
Sex (_index) category 2MB ...
Race (_index) category 2MB ...
Ethnicity (_index) category 2MB ...
BMI (_index) category 2MB ...
... ...
Method (_index) category 2MB ...
CITE-Seq panel (_index) category 2MB ...
Reference (_index) category 2MB ...
Institute (_index) category 2MB ...
Creation date (_index) float64 2MB dask.array<chunksize=(34382,), meta=np.ndarray>
Annotation (_index) category 2MB ...
Attributes:
is_backed: Trueadata.obs["SARS-CoV-2 PCR"]
<xarray.DataArray 'SARS-CoV-2 PCR' (_index: 275056)> Size: 2MB dask.array<from-zarr, shape=(275056,), dtype=float64, chunksize=(34382,), chunktype=numpy.ndarray> Coordinates: * _index (_index) object 2MB 'COV002_AAACCCAAGAGTCTTC-1' ... 'COV037_TTTG...
adata.obs["28-day death"]
<xarray.DataArray '28-day death' (_index: 275056)> Size: 2MB dask.array<from-zarr, shape=(275056,), dtype=float64, chunksize=(34382,), chunktype=numpy.ndarray> Coordinates: * _index (_index) object 2MB 'COV002_AAACCCAAGAGTCTTC-1' ... 'COV037_TTTG...
These are both xarray DataArrays, with Dask backing data. We’ll use these columns to form an interesting subset. Usually we would hope these are stored as boolean, but floats will work just the same. Note that the indexing data needs to be in memory first before it can be used. This will likely be improved in the future. So let’s start by getting just the COVID-19 positive patients - we’ll separate by mortality later.
has_covid = adata.obs["SARS-CoV-2 PCR"].data.compute().astype("bool")
has_covid_adata = adata[has_covid, :]
has_covid_adata
obs/SARS-CoV-2 PCR/7 accessed!
obs/SARS-CoV-2 PCR/6 accessed!
obs/SARS-CoV-2 PCR/5 accessed!
obs/SARS-CoV-2 PCR/3 accessed!
obs/SARS-CoV-2 PCR/0 accessed!
obs/SARS-CoV-2 PCR/2 accessed!
obs/SARS-CoV-2 PCR/4 accessed!
obs/SARS-CoV-2 PCR/1 accessed!
View of AnnData object with n_obs × n_vars = 140014 × 24740
obs: 'orig.ident', 'Age', 'Sex', 'Race', 'Ethnicity', 'BMI', 'Pre-existing heart disease', 'Pre-existing lung disease', 'Pre-existing kidney disease', 'Pre-existing diabetes', 'Pre-existing hypertension', 'Pre-existing immunocompromised condition', 'Smoking', 'SARS-CoV-2 PCR', 'SARS-CoV-2 Ab', 'Symptomatic', 'Admitted to hospital', 'Highest level of respiratory support', 'Vasoactive agents required during hospitalization', '28-day death', '28-day outcome', 'Disease classification', 'Organ System', 'Source', 'Days since hospital admission', 'SOFA', 'Technology', 'Method', 'CITE-Seq panel', 'Reference', 'Institute', 'Creation date', 'Annotation'
var: 'feature_type', 'gene_id'
obsm: 'X_umap'
layers: 'X_csc'
That was pretty fast! Now we’re getting somewhere. Let’s look at the cell types present in our dataset.
We immediately are able to see the available categories here. Not too much data has been read in yet - only what we need. COVID 19 is known to act (https://pubmed.ncbi.nlm.nih.gov/34861051/) on CD4, Neutorphil and CD8+ cells inversely in suriviors vs. non-surivivors, so let’s focus on those.
has_covid_adata.obs["Annotation"].dtype
CategoricalDtype(categories=['B cell', 'Baso Mast', 'CD4+ T-cell', 'CD8+ T-cell',
'Doublet', 'Epithelial cell', 'Macrophage',
'Macrophage:Alveolar', 'NK', 'Neutrophil', 'Plasma cell',
'cDC', 'gd T-cell', 'pDC'],
, ordered=False, categories_dtype=str)
affected_cell_types = ["CD4+ T-cell", "CD8+ T-cell", "Neutrophil"]
# Note we have to load the data into memory via .data[()] in order to index the AnnData object
affected_cell_types_adata = has_covid_adata[
has_covid_adata.obs["Annotation"].data[()].isin(affected_cell_types), :
]
has_covid_adata
obs/Annotation/codes/1 accessed!
obs/Annotation/codes/0 accessed!
View of AnnData object with n_obs × n_vars = 140014 × 24740
obs: 'orig.ident', 'Age', 'Sex', 'Race', 'Ethnicity', 'BMI', 'Pre-existing heart disease', 'Pre-existing lung disease', 'Pre-existing kidney disease', 'Pre-existing diabetes', 'Pre-existing hypertension', 'Pre-existing immunocompromised condition', 'Smoking', 'SARS-CoV-2 PCR', 'SARS-CoV-2 Ab', 'Symptomatic', 'Admitted to hospital', 'Highest level of respiratory support', 'Vasoactive agents required during hospitalization', '28-day death', '28-day outcome', 'Disease classification', 'Organ System', 'Source', 'Days since hospital admission', 'SOFA', 'Technology', 'Method', 'CITE-Seq panel', 'Reference', 'Institute', 'Creation date', 'Annotation'
var: 'feature_type', 'gene_id'
obsm: 'X_umap'
layers: 'X_csc'
We can now check the claim of the above-linked paper. They claim “At admission, patients who later succumbed to COVID-19 had significantly lower frequencies of all memory CD8+ T cell subsets, resulting in increased CD4-to-CD8 T cell and neutrophil-to-CD8 T cell ratios.” Is this true? We can check very easily! Indeed it is!
died = has_covid_adata.obs["28-day death"].data.compute().astype("bool")
obs/28-day death/1 accessed!
obs/28-day death/5 accessed!
obs/28-day death/0 accessed!
obs/28-day death/3 accessed!
obs/28-day death/6 accessed!
obs/28-day death/4 accessed!
obs/28-day death/7 accessed!
obs/28-day death/2 accessed!
/var/folders/_z/88mtpv4x1nl6lkvd86wsb9sw0000gn/T/ipykernel_132/3143817020.py:1: RuntimeWarning: invalid value encountered in cast
died = has_covid_adata.obs["28-day death"].data.compute().astype("bool")
cd8 = has_covid_adata.obs["Annotation"].data[()] == "CD8+ T-cell"
cd4 = has_covid_adata.obs["Annotation"].data[()] == "CD4+ T-cell"
neutrophil = has_covid_adata.obs["Annotation"].data[()] == "Neutrophil"
cd8_count_survived = has_covid_adata[cd8 & ~died, :].shape[0]
cd4_count_survived = has_covid_adata[cd4 & ~died, :].shape[0]
neutrophil_count_survived = has_covid_adata[neutrophil & ~died, :].shape[0]
cd8_count_mortality = has_covid_adata[cd8 & died, :].shape[0]
cd4_count_mortality = has_covid_adata[cd4 & died, :].shape[0]
neutrophil_count_mortality = has_covid_adata[neutrophil & died, :].shape[0]
print("Patients who Survived:")
print("----------------------")
print(f"CD4/CD8 Ratio: {cd4_count_survived / cd8_count_survived}")
print(f"Neutrophil/CD8 Ratio: {neutrophil_count_survived / cd8_count_survived}")
Patients who Survived:
----------------------
CD4/CD8 Ratio: 1.4132880871584212
Neutrophil/CD8 Ratio: 6.4724057867476334
print("Patients who Died:")
print("----------------------")
print(f"CD4/CD8 Ratio: {cd4_count_mortality / cd8_count_mortality}")
print(f"Neutrophil/CD8 Ratio: {neutrophil_count_mortality / cd8_count_mortality}")
Patients who Died:
----------------------
CD4/CD8 Ratio: 2.9249146757679183
Neutrophil/CD8 Ratio: 14.858788395904437
Remarkable, we immediately see that this dataset confirms that result reported. And this short confirmatory analysis all took place without every loading the omics data (from X) into memory. Indeed, all of the above code should cumulatively have taken no longer than 15 seconds to run. But what if we do want to look at the raw omics data? Let’s try to do that, using a few cell-type markers reported from this dataset: https://www.medrxiv.org/content/10.1101/2020.11.20.20227355v1.full.pdf. These should appear clearly across certain cell types when visualized.
Before we go further to visualize gene expression, let’s note the size of the chunks for X_csc (which we will use to visualize gene expression because it is column-efficient) - these are quite large for fetching individual columns as we will do below. However, a larger chunk size can be beneficial for other applications, such as PCA, where big groups of row data (ideally from dense or CSR matrices) is likely better than tiny chunks as hte overhead of individual fetch calls is reduced.
adata.layers["X_csc"]
|
|||||||||||||
To fix this problem, let’s re-read the data with smaller chunk sizes via read_elem_lazy. This will reduce overhead without incurring any cost.
adata.layers["X_csc"] = read_elem_lazy(zarr.open(store, mode="r")["layers"]["X_csc"], chunks=(adata.shape[0], 1))
adata.layers["X_csc"]
|
|||||||||||||
Note
Note that we have to explicitly look for var_names if not load_annotation_index to get the genes subset we want because we didn’t load the index. That is var_names is just a string-transformed pandas.RangeIndex
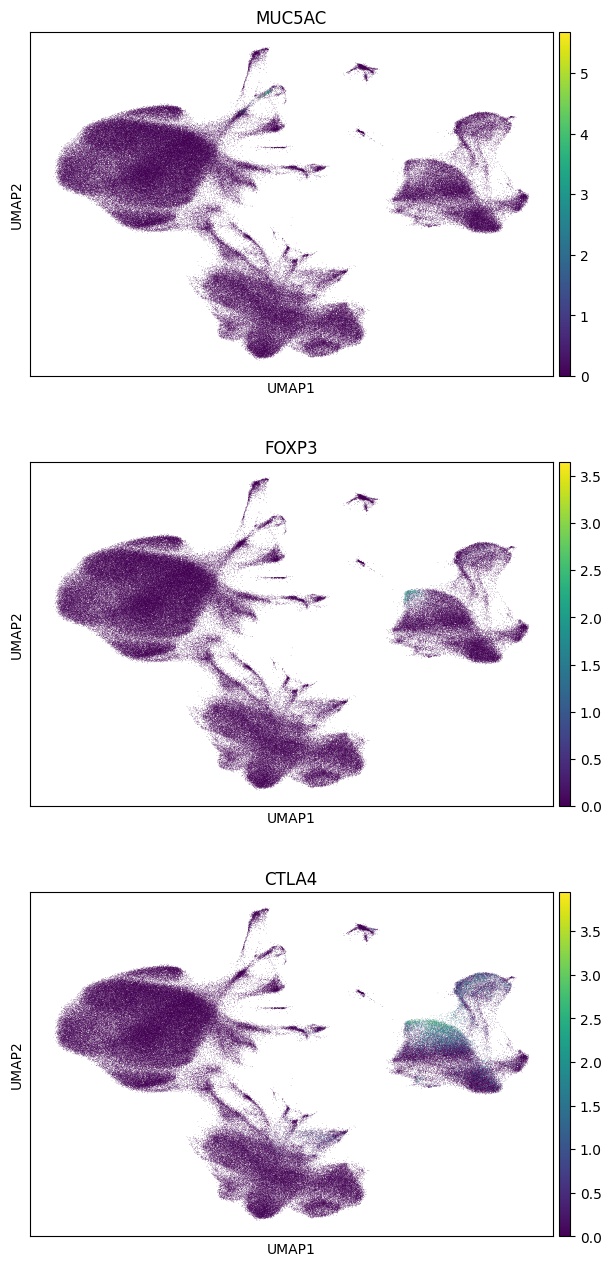
genes = ["MUC5AC", "FOXP3", "CTLA4"]
if not load_annotation_index:
gene_subset_adata = adata[:, adata.var['var_names'].isin(genes)]
else:
gene_subset_adata = adata[:, genes]
gene_subset_adata
View of AnnData object with n_obs × n_vars = 275056 × 3
obs: 'orig.ident', 'Age', 'Sex', 'Race', 'Ethnicity', 'BMI', 'Pre-existing heart disease', 'Pre-existing lung disease', 'Pre-existing kidney disease', 'Pre-existing diabetes', 'Pre-existing hypertension', 'Pre-existing immunocompromised condition', 'Smoking', 'SARS-CoV-2 PCR', 'SARS-CoV-2 Ab', 'Symptomatic', 'Admitted to hospital', 'Highest level of respiratory support', 'Vasoactive agents required during hospitalization', '28-day death', '28-day outcome', 'Disease classification', 'Organ System', 'Source', 'Days since hospital admission', 'SOFA', 'Technology', 'Method', 'CITE-Seq panel', 'Reference', 'Institute', 'Creation date', 'Annotation'
var: 'feature_type', 'gene_id'
obsm: 'X_umap'
layers: 'X_csc'
Now we want to visualize the data. But we need to bring the data into memory for that. Luckily, this is no problem as there is a convenient to_memory function provided with the AnnData object. Also, we once again note the presence of an X_csc layer - the X layer is sparse CSR format which will not be very good for reading column data efficiently. Thus we use the X_csc matrix for fast access to full cell information given a subset of genes of interest.
Note
If you used the load_annotation_index=False argument to read in the data, you definitely don’t want to drop the obs_names and var_names columns as they are not the in xarray.Dataset.coords and therefore will be dropped otherwise. Downstread, this will prevent e.g., subsetting by gene names.
obs_keys_to_exclude = [
v for v in gene_subset_adata.obs.keys() if v not in ({ "Annotation" }).union({ "obs_names" } if not load_annotation_index else {})
]
data_for_memory = ad.AnnData(
obs = gene_subset_adata.obs.ds.drop_vars(obs_keys_to_exclude),
obsm = gene_subset_adata.obsm,
var = gene_subset_adata.var.ds.drop_vars(set(gene_subset_adata.var.keys()).difference({ "var_names" } if not load_annotation_index else {})),
X = gene_subset_adata.layers["X_csc"]
)
gene_subset_adata_in_memory = data_for_memory.to_memory()
layers/X_csc/indptr/0 accessed!
layers/X_csc/data/961 accessed!
layers/X_csc/data/158 accessed!
layers/X_csc/indices/79 accessed!
layers/X_csc/indices/480 accessed!
layers/X_csc/data/404 accessed!
layers/X_csc/indices/202 accessed!
obsm/X_umap/3.1 accessed!
obsm/X_umap/2.0 accessed!
obsm/X_umap/1.1 accessed!
obsm/X_umap/2.1 accessed!
obsm/X_umap/0.0 accessed!
obsm/X_umap/1.0 accessed!
obsm/X_umap/0.1 accessed!
obsm/X_umap/3.0 accessed!
Note the data accessed (see the first cell with the store declaration for cell in which this was printed) - basically only UMAP coordinates and a few chunks of the underlying sparse data. The above should have only taken about 5 seconds. Finally, we can use this in-memory object in scanpy to visualize the data. Indeed, the genes only show up in subsets of the clusers because the paper reports a finer grained cell typing than is given in the AnnData object. For example, from the paper, “preliminary phenotyping of CD4 T cell subsets revealed…regulatory (FOXP3, CTLA4)….cells.” And indeed, we see those genes appearing within, but not overall in, the CD4+ T-Cell cluster.
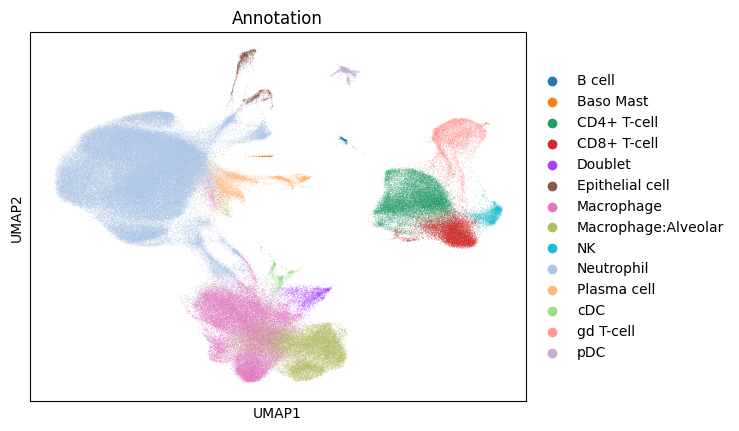
sc.pl.umap(gene_subset_adata_in_memory, color="Annotation")
sc.pl.umap(gene_subset_adata_in_memory, color=genes, ncols=1)
In the future, we will work on enabling xarray across X, obsm, and all other attributes to give a truly unified API (currently, the obsm, varp etc. classes are still the same, albeit lazy). Furthermore, we hope to allow for point-to-point writing as well as overwriting i.e., without having to read the data into memory. Onwards!